Tofu Applications
Data lineage
When opening a dataset ressource via the ressource manager, the data lineage will display a high level overview of all things data in your project. The graph displays how data and Tofu applications relate to each other.
Data in the lineage flows from left to right and is processed in different nodes connected with each other. Depending on the color of the node, a different Tofu application is taking part in it's processing.
Pipelines
Pipelines are custom python code that make up your application. Pipelines can be triggered via the click of a button in modules or via the via the API. Pipelines execute user code to transform, enhance or predict data with AI or classical SQL statements. Learn more in the SDK section.
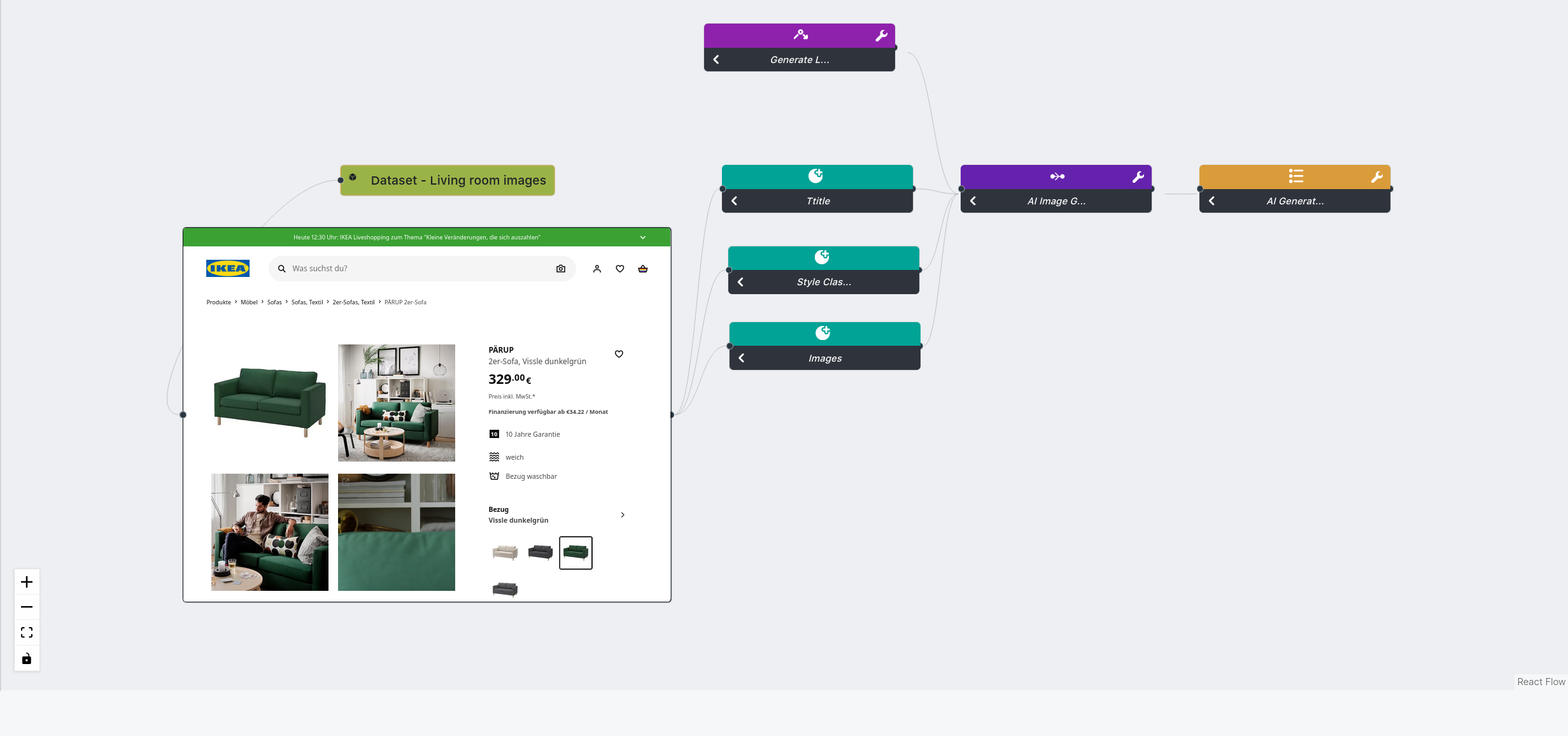
creating pipelines
Datasets
The basic building block is your dataset. You can find it in the data lineage as a green box. Below the dataset a sample of your data is displayed.
Ontology
The ontology defines the business logic of your application or AI enabled organization. It presents an overview of modules and data object types.
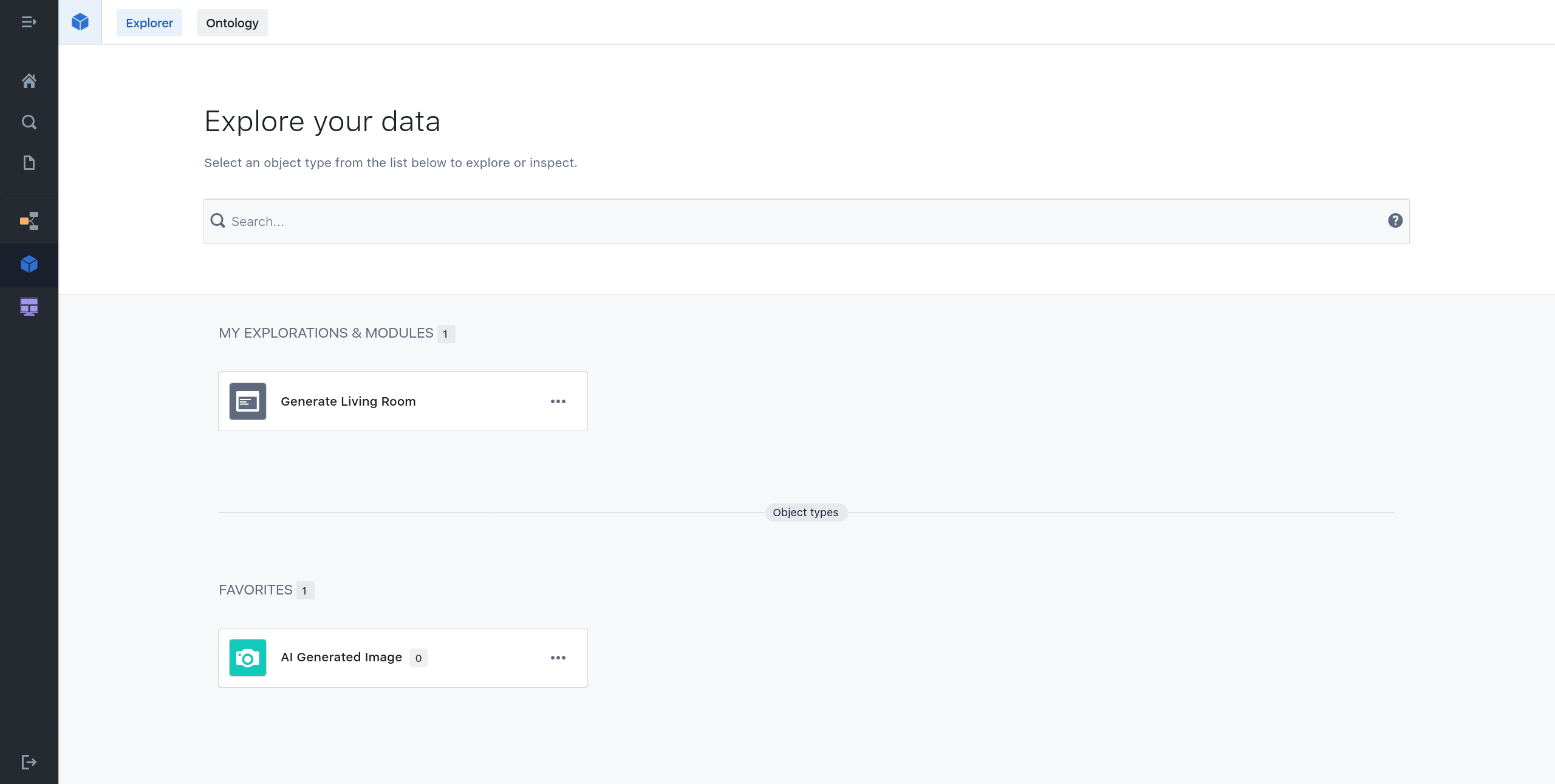
Data object types
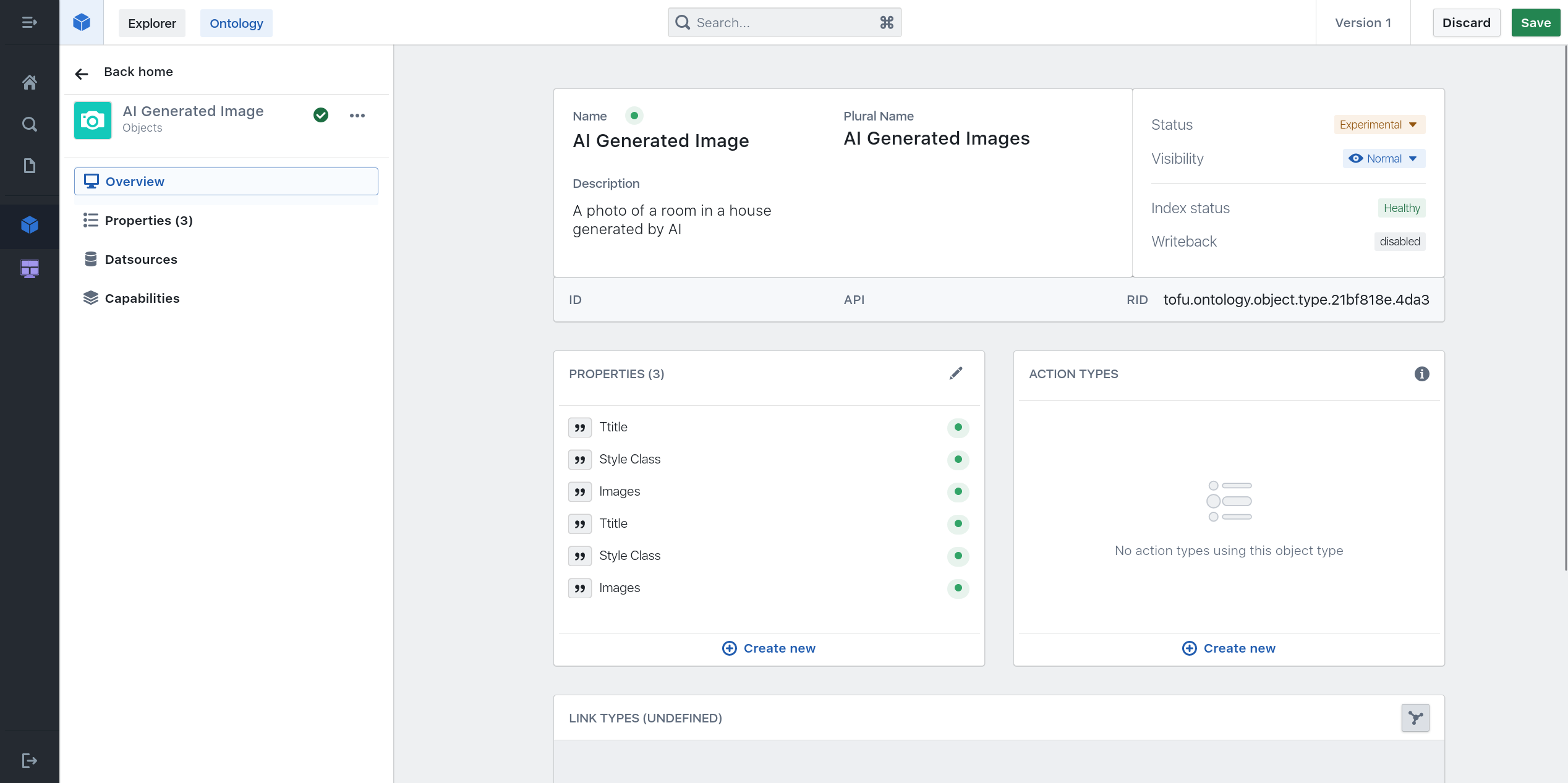
Data object types are the backbone of working with data in the platform. Data object types resemble real life entities that take part in achieving the usecase of your application or AI enabled organization.
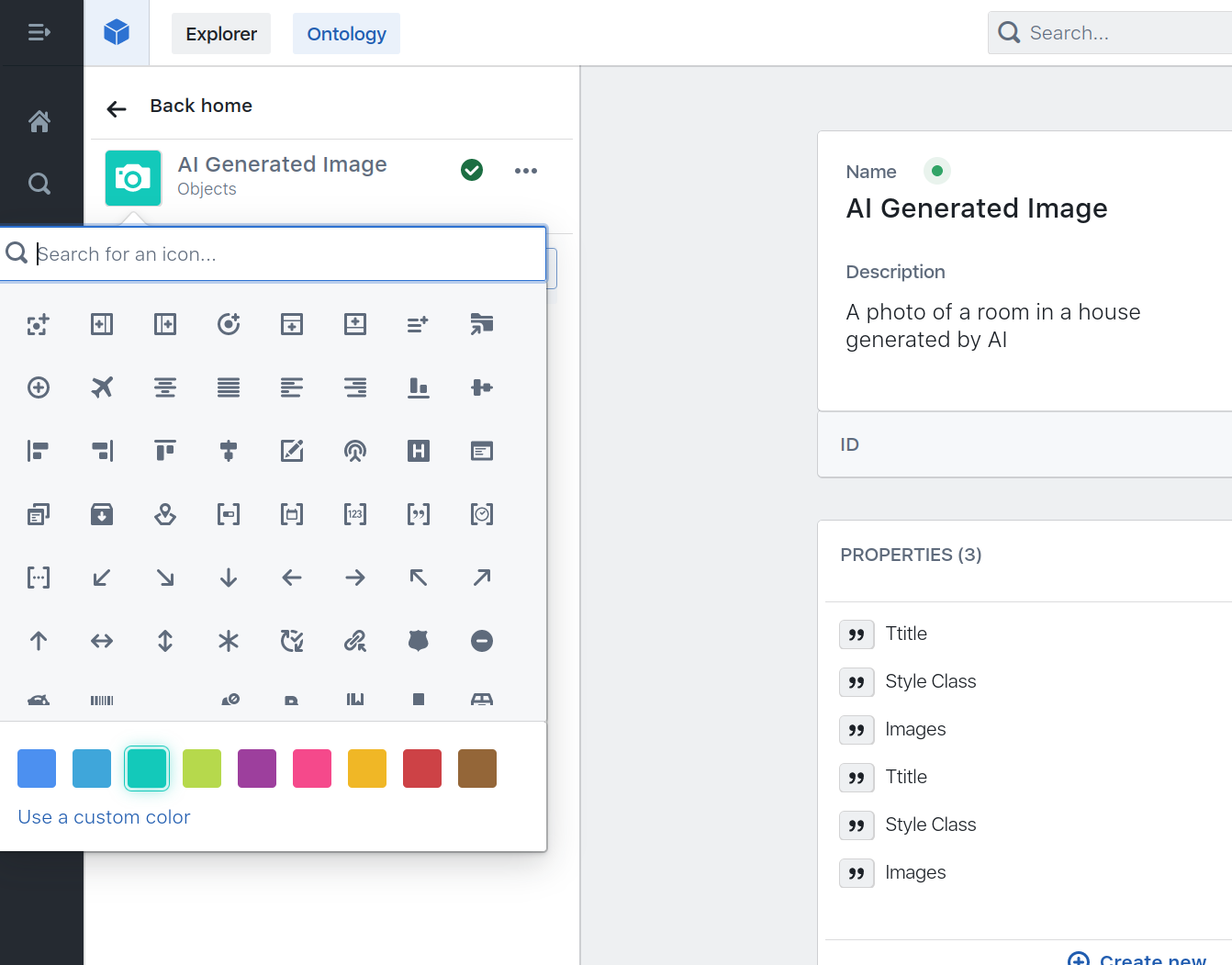
Pick a icon and color to easily find back your data object type in other parts of the application (e.g. modules) by clicking the icon in the left sidebar.
creating data object types
Modules
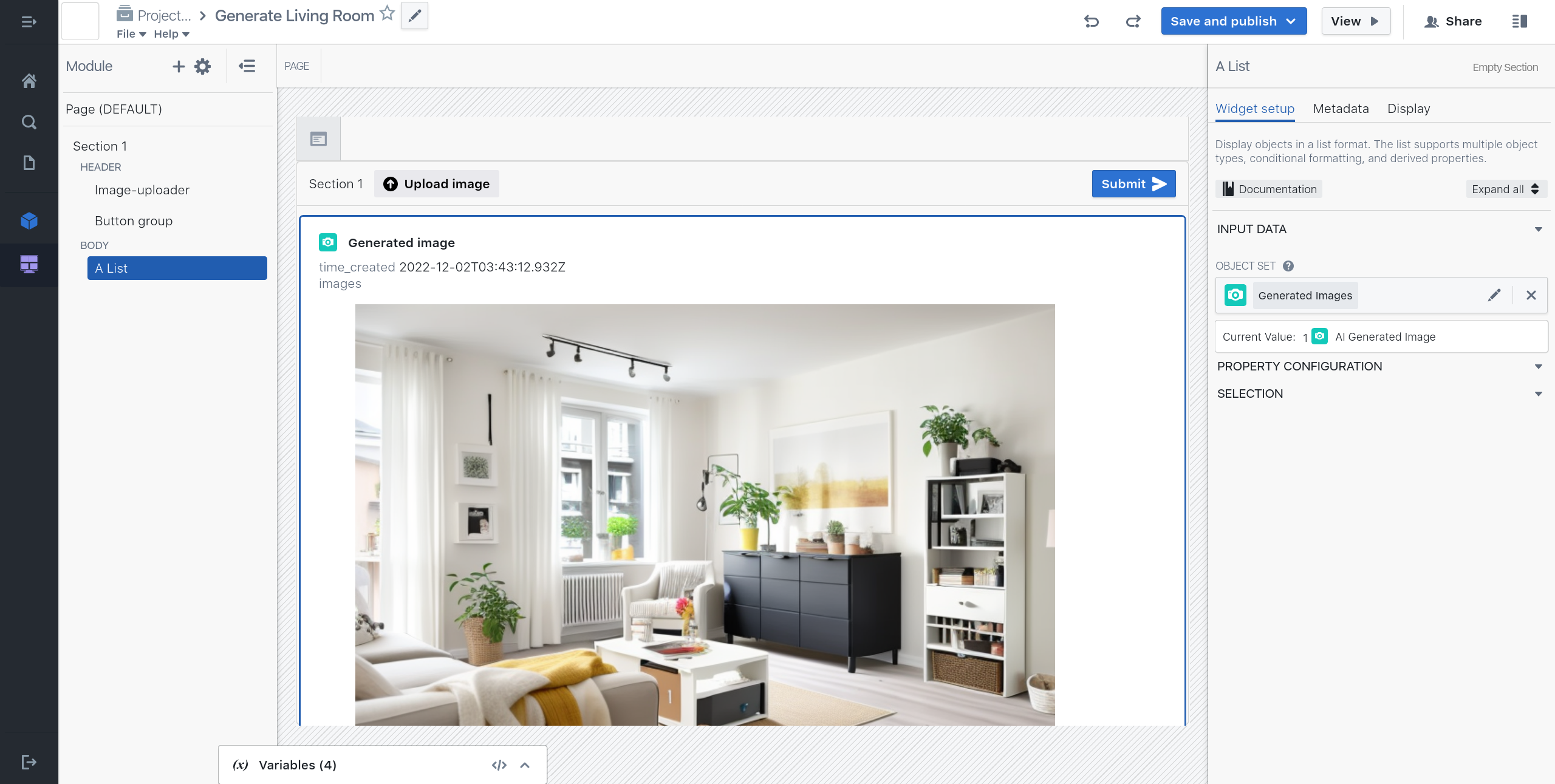
Trigger
Trigger execute pipelines. The can be assigned to a button in a module or triggered via the API externally.